
While augmented reality (AR) enables new ways to play, tell stories, and explore ideas rooted in the physical world, authoring personalized AR content remains difficult for non-experts, often requiring professional tools and time. Prior systems have explored AI-driven XR design but typically rely on manually defined VR environments and fixed asset libraries, limiting creative flexibility and real-world relevance. We introduce ImaginateAR, the first mobile tool for AI-assisted AR authoring to combine offline scene understanding, fast 3D asset generation, and LLMs—enabling users to create outdoor scenes through natural language interaction. For example, saying "a dragon enjoying a campfire" (P7) prompts the system to generate and arrange relevant assets, which can then be refined manually. Our technical evaluation shows that our custom pipelines produce more accurate outdoor scene graphs and generate 3D meshes faster than prior methods. A three-part user study (N=20) revealed preferred roles for AI, how users create in free-form use, and design implications for future AR authoring tools. ImaginateAR takes a step toward empowering anyone to create AR experiences anywhere—simply by speaking their imagination.
© 2025 Jae
Jae (Jaewook) Lee
HCI Researcher Studying Augmented Reality (AR), Human-AI interaction, and Accessibility.
About Me

Jae (Jaewook/재욱) Lee
HCI Ph.D. StudentHey there! I'm Jae. I’m a Human–Computer Interaction (HCI) Ph.D. student at the University of Washington, advised by Prof. Jon Froehlich. I am currently supported by the NSF Graduate Research Fellowship (NSF GRFP). My research lies at the intersection of Augmented Reality (AR), Human–AI Interaction, and Accessibility. I design AI-powered AR systems that continuously understand people and their surroundings to provide tailored assistance in everyday activities. Through implementing and evaluating these systems, I aim to explore their potential to assist not only the general public but also blind or low-vision (BLV) and deaf or hard-of-hearing (DHH) communities. I’m passionate about "re-imagining AI-powered AR for all".
Outside research, I hang out with friends, play tennis, cook Korean food, listening to music, and play/make video games!
I'm open to chatting about research & pretty much anything else! The best way to reach me is to my email: jaewook4 [at] cs [dot] washington [dot] edu
Education
-
2022 - Present
University of Washington
Doctorate Degree -
2018-2022
University of Illinois Urbana-Champaign
Bachelor Degree
Experience
-
Jun. 2025 - Sep. 2025
Microsoft Research
Research Scientist Intern -
Jun. 2024 - Oct. 2024
Niantic
Research Scientist Intern -
Jun. 2023 - Nov. 2023
Meta
Research Scientist Intern -
Jun. 2022 - Aug. 2022
NASA
AR/VR Intern
Publications
-

ISMAR '25 Workshop
SonoCraftAR: Towards Supporting Personalized Authoring of Sound-Reactive AR Interfaces by Deaf and Hard of Hearing Users
Augmented reality (AR) has shown promise for supporting Deaf and hard-of-hearing (DHH) individuals by captioning speech and visualizing environmental sounds, yet existing systems do not allow users to create personalized sound visualizations. We present SonoCraftAR, a proof-of-concept prototype that empowers DHH users to author custom sound-reactive AR interfaces using typed natural language input. SonoCraftAR integrates real-time audio signal processing with a multi-agent LLM pipeline that procedurally generates animated 2D interfaces via a vector graphics library. The system extracts the dominant frequency of incoming audio and maps it to visual properties such as size and color, making the visualizations respond dynamically to sound. This early exploration demonstrates the feasibility of open-ended sound-reactive AR interface authoring and discusses future opportunities for personalized, AI-assisted tools to improve sound accessibility.
-

CHI '25 LBW 25 April 2025
Walkie-Talkie: Exploring Longitudinal Natural Gaze, LLMs, and VLMs for Query Disambiguation in XR
Everyday conversations are often ambiguous, which we resolve using nonverbal cues like gaze and pointing. To enable such low-effort interactions with voice assistants (VAs), we explore how large language models (LLMs) and vision-language models (VLMs) can leverage longitudinal natural gaze signals. We introduce Walkie-Talkie, a multimodal VA for extended reality (XR) that uses gaze dynamics to disambiguate queries. Through iterative design, our system transforms gaze data—capturing targets, duration, and spatial relationships—into text and/or image for LLM and VLM processing alongside spoken word timing. In a controlled VR study (N=12), Walkie-Talkie outperformed a baseline requiring explicit gaze input, and subsequent AR evaluations explored its real-world feasibility. Our findings highlight the potential of multimodal foundation models for natural, accurate gaze and speech interactions in wearable XR. We conclude by discussing future directions for designing always-available, context-aware AI agents in XR glasses.
-

ISMAR '24 Workshop 02 December 2024
🏆 Best Paper
Towards AI-Powered AR for Enhancing Sports Playability for People with Low Vision: An Exploration of ARSports
People with low vision (LV) experience challenges in visually tracking balls and players in sports like basketball and tennis, which can adversely impact their participation and health. We introduce ARSports, a wearable AR research prototype that overlays instance segmentation masks in near real-time for improving sports accessibility. To create ARSports, we manually collected and annotated novel first-person perspective sports datasets, fine-tuned instance segmentation models using this labeled data, and built an initial wearable AR prototype by combining the ZED Mini stereo camera with the Oculus Quest 2 VR headset. Our evaluations suggest that combining real-time computer vision and augmented reality to create scene-aware visual augmentations is a promising approach to enhancing sports participation for LV individuals. We contribute open-sourced egocentric basketball and tennis datasets and models, as well as insights and design recommendations from our pilot study with an LV research team member.
-

UIST '24 11 October 2024
🏆 Best Paper
CookAR: Affordance Augmentations in Wearable AR to Support Kitchen Tool Interactions for People with Low Vision
Cooking is a central activity of daily living, supporting independence as well as mental and physical health. However, prior work has highlighted key barriers for people with low vision (LV) to cook, particularly around safely interacting with tools, such as sharp knives or hot pans. Drawing on recent advancements in computer vision (CV), we present CookAR, a head-mounted AR system with real-time object affordance augmentations to support safe and efficient interactions with kitchen tools. To design and implement CookAR, we collected and annotated the first egocentric dataset of kitchen tool affordances, fine-tuned an affordance segmentation model, and developed an AR system with a stereo camera to generate visual augmentations. To validate CookAR, we conducted a technical evaluation of our fine-tuned model as well as a qualitative lab study with 10 LV participants for suitable augmentation design. Our technical evaluation demonstrates that our model outperforms the baseline on our tool affordance dataset, while our user study indicates a preference for affordance augmentations over the traditional whole object augmentations.
-

UIST '24 Demo 11 October 2024
Embodied AR Language Learning Through Everyday Object Interactions: A Demonstration of EARLL
Learning a new language is an exciting and important, yet often challenging journey. To support foreign language acquisition, we introduce EARLL, an embodied and context-aware language learning application for AR glasses. EARLL leverages real-time computer vision and depth sensing to continuously segment and localize objects in users' surroundings, check for hand-object manipulations, and then subtly trigger foreign vocabulary prompts relevant to that object. In this demo paper, we present our initial EARLL prototype and highlight current challenges and future opportunities with always-available, wearable, embodied AR language learning.
-

USINEX '24 14 August 2024
When the User Is Inside the User Interface: An Empirical Study of UI Security Properties in Augmented Reality
Augmented reality (AR) experiences place users inside the user interface (UI), where they can see and interact with three-dimensional virtual content. This paper explores UI security for AR platforms, for which we identify three UI security-related properties: Same Space (how does the platform handle virtual content placed at the same coordinates?), Invisibility (how does the platform handle invisible virtual content?), and Synthetic Input (how does the platform handle simulated user input?). We demonstrate the security implications of different instantiations of these properties through five proof-of-concept attacks between distrusting AR application components (i.e., a main app and an included library)\dash including a clickjacking attack and an object erasure attack. We then empirically investigate these UI security properties on five current AR platforms: ARCore (Google), ARKit (Apple), Hololens (Microsoft), Oculus (Meta), and WebXR (browser). We find that all platforms enable at least three of our proof-of-concept attacks to succeed. We discuss potential future defenses, including applying lessons from 2D UI security and identifying new directions for AR UI security.
-

CHI '24 11 May 2024
GazePointAR: A Context-Aware Multimodal Voice Assistant for Pronoun Disambiguation in Wearable Augmented Reality
Voice assistants (VAs) like Siri and Alexa are transforming human-computer interaction; however, they lack awareness of users’ spatiotemporal context, resulting in limited performance and unnatural dialogue. We introduce GazePointAR, a fully-functional context-aware VA for wearable augmented reality that leverages eye gaze, pointing gestures, and conversation history to disambiguate speech queries. With GazePointAR, users can ask “what’s over there?” or “how do I solve this math problem?” simply by looking and/or pointing. We evaluated GazePointAR in a three-part lab study (N=12): (1) comparing GazePointAR to two commercial systems, (2) examining GazePointAR’s pronoun disambiguation across three tasks; (3) and an open-ended phase where participants could suggest and try their own context-sensitive queries. Participants appreciated the naturalness and human-like nature of pronoun-driven queries, although sometimes pronoun use was counter-intuitive. We then iterated on GazePointAR and conducted a first-person diary study examining how GazePointAR performs in-the-wild. We conclude by enumerating limitations and design considerations for future context-aware VAs.
-
CHI '24 11 May 2024
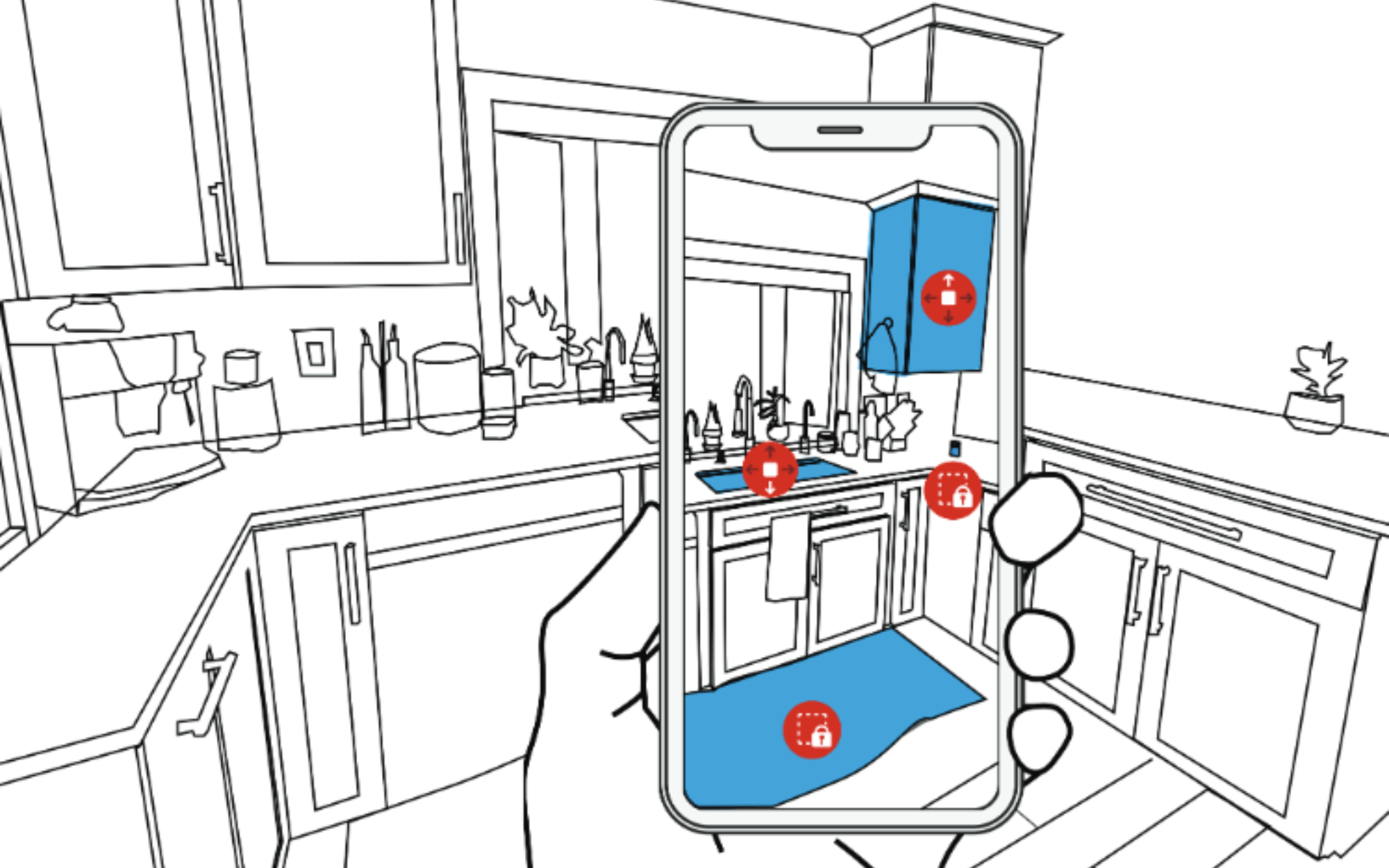
RASSAR: Room Accessibility and Safety Scanning in Augmented Reality
The safety and accessibility of our homes is critical to quality of life and evolves as we age, become ill, host guests, or experience life events such as having children. Researchers and health professionals have created assessment instruments such as checklists that enable homeowners and trained experts to identify and mitigate safety and access issues. With advances in computer vision, augmented reality (AR), and mobile sensors, new approaches are now possible. We introduce RASSAR, a mobile AR application for semi-automatically identifying, localizing, and visualizing indoor accessibility and safety issues such as an inaccessible table height or unsafe loose rugs using LiDAR and real-time computer vision. We present findings from three studies: a formative study with 18 participants across five stakeholder groups to inform the design of RASSAR, a technical performance evaluation across ten homes demonstrating state-of-the-art performance, and a user study with six stakeholders. We close with a discussion of future AI-based indoor accessibility assessment tools, RASSAR’s extensibility, and key application scenarios.
-

UIST '23 Demo 29 October 2023
Towards Real-time Computer Vision and Augmented Reality to Support Low Vision Sports: A Demonstration of ARTennis
Individuals with low vision (LV) can experience vision-related challenges when participating in sports, especially those with fast-moving objects. We introduce ARTennis, a prototype for wearable augmented reality (AR) that utilizes real-time computer vision (CV) to enhance the visual saliency of tennis balls. Preliminary findings indicate that while ARTennis is helpful, combining both visual and auditory cues may be more effective. As AR and CV technologies continue to improve, we expect head-worn AR to broaden the inclusivity of sports.
-
UIST '23 Demo 29 October 2023
Towards Designing a Context-Aware Multimodal Voice Assistant for Pronoun Disambiguation: A Demonstration of GazePointAR
Voice assistants (VAs) like Siri and Alexa have transformed how humans interact with technology; however, their inability to consider a user’s spatiotemporal context, such as surrounding objects, drammatically limits natural dialogue. In this demo paper, we introduce GazePointAR, a wearable augmented reality (AR) system that resolves ambiguity in speech queries using eye gaze, pointing gesture, and conversation history. With GazePointAR, a user can ask “what’s over there?” or “how do I solve this math problem?” simply by looking and/or pointing. We describe GazePointAR’s design and highlight supported use cases.
-
ASSETS '23 Demo 22 October 2023
A Demonstration of RASSAR: Room Accessibility and Safety Scanning in Augmented Reality
In this demo paper, we introduce RASSAR, a mobile AR application for semi-automatically identifying, localizing, and visualizing indoor accessibility and safety issues using LiDAR and real-time computer vision. Our prototype supports four classes of detection problems: inaccessible object dimensions (e.g., table height), inaccessible object positions (e.g., a light switch out of reach), the presence of unsafe items (e.g., scissors), and the lack of proper assistive devices (e.g., grab bars). RASSAR’s design was informed by a formative interview study with 18 participants from five key stakeholder groups, including wheelchair users, blind and low vision participants, families with young children, and caregivers. Our envisioned use cases include vacation rental hosts, new caregivers, or people with disabilities themselves documenting issues in their homes or rental spaces and planning renovations. We present key findings from our formative interviews, the design of RASSAR, and results from an initial performance evaluation.
-
TOCHI '23 10 June 2023
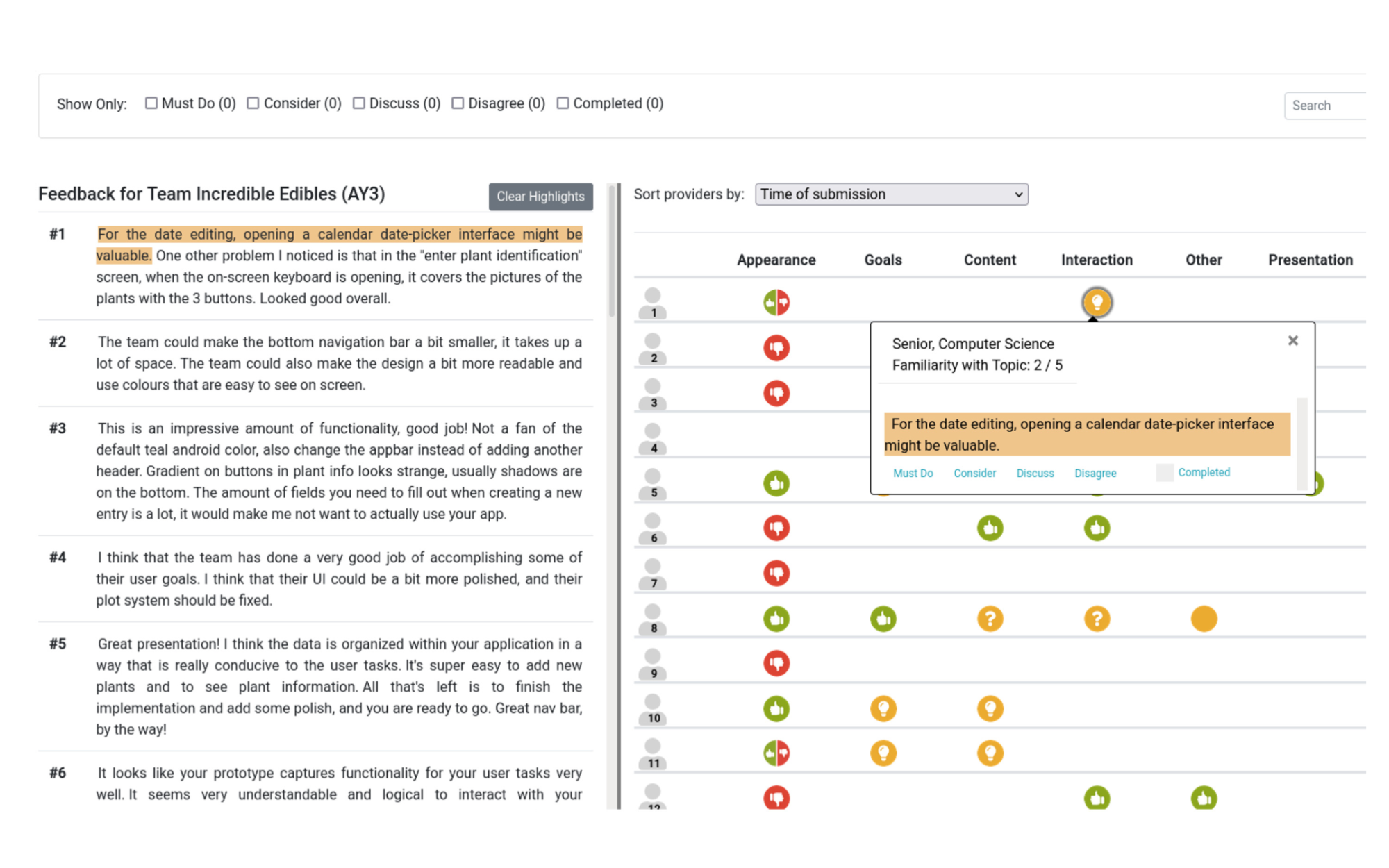
Visualizing Topics and Opinions Helps Students Interpret Large Collections of Peer Feedback for Creative Projects
We deployed a feedback visualization tool to learn how students used the tool for interpreting feedback from peers and teaching assistants. The tool visualizes the topic and opinion structure in a collection of feedback and provides interaction for reviewing providers’ backgrounds. A total of 18 teams engaged with the tool to interpret feedback for course projects. We surveyed students (N = 69) to learn about their sensemaking goals, use of the tool to accomplish those goals, and perceptions of specific features. We interviewed students (N = 12) and TAs (N = 2) to assess the tool’s impact on students’ review processes and course instruction. Students discovered valuable feedback, assessed project quality, and justified design decisions to teammates by exploring specific icon patterns in the visualization. The interviews revealed that students mimicked strategies implemented in the tool when reviewing new feedback without the tool. Students found the benefits of the visualization outweighed the cost of labeling feedback.
-

CSCW '23 16 April 2023
To Err is AI: Imperfect Interventions and Repair in a Conversational Agent Facilitating Group Chat Discussions
Conversational agents (CAs) can analyze online conversations using natural language techniques and effectively facilitate group discussions by sending supervisory messages. However, if a CA makes imperfect interventions, users may stop trusting the CA and discontinue using it. In this study, we demonstrate how inaccurate interventions of a CA and a conversational repair strategy can influence user acceptance of the CA, members' participation in the discussion, perceived discussion experience between the members, and group performance. We built a CA that encourages the participation of members with low contributions in an online chat discussion in which a small group (3-6 members) performs a decision-making task. Two types of errors can occur when detecting under-contributing members: 1) false-positive (FP) errors happen when the CA falsely identifies a member as under-contributing and 2) false-negative (FN) errors occur when the CA misses detecting an under-contributing member. We designed a conversational repair strategy that gives users a chance to contest the detection results and the agent sends a correctional message if an error is detected. Through an online study with 175 participants, we found that participants who received FN error messages reported higher acceptance of the CA and better discussion experience, but participated less compared to those who received FP error messages. The conversational repair strategy moderated the effect of errors such as improving the perceived discussion experience of participants who received FP error messages. Based on our findings, we offer design implications for which model should be selected by practitioners between high precision (i.e., fewer FP errors) and high recall (i.e., fewer FN errors) models depending on the desired effects. When frequent FP errors are expected, we suggest using the conversational repair strategy to improve the perceived discussion experience.
-
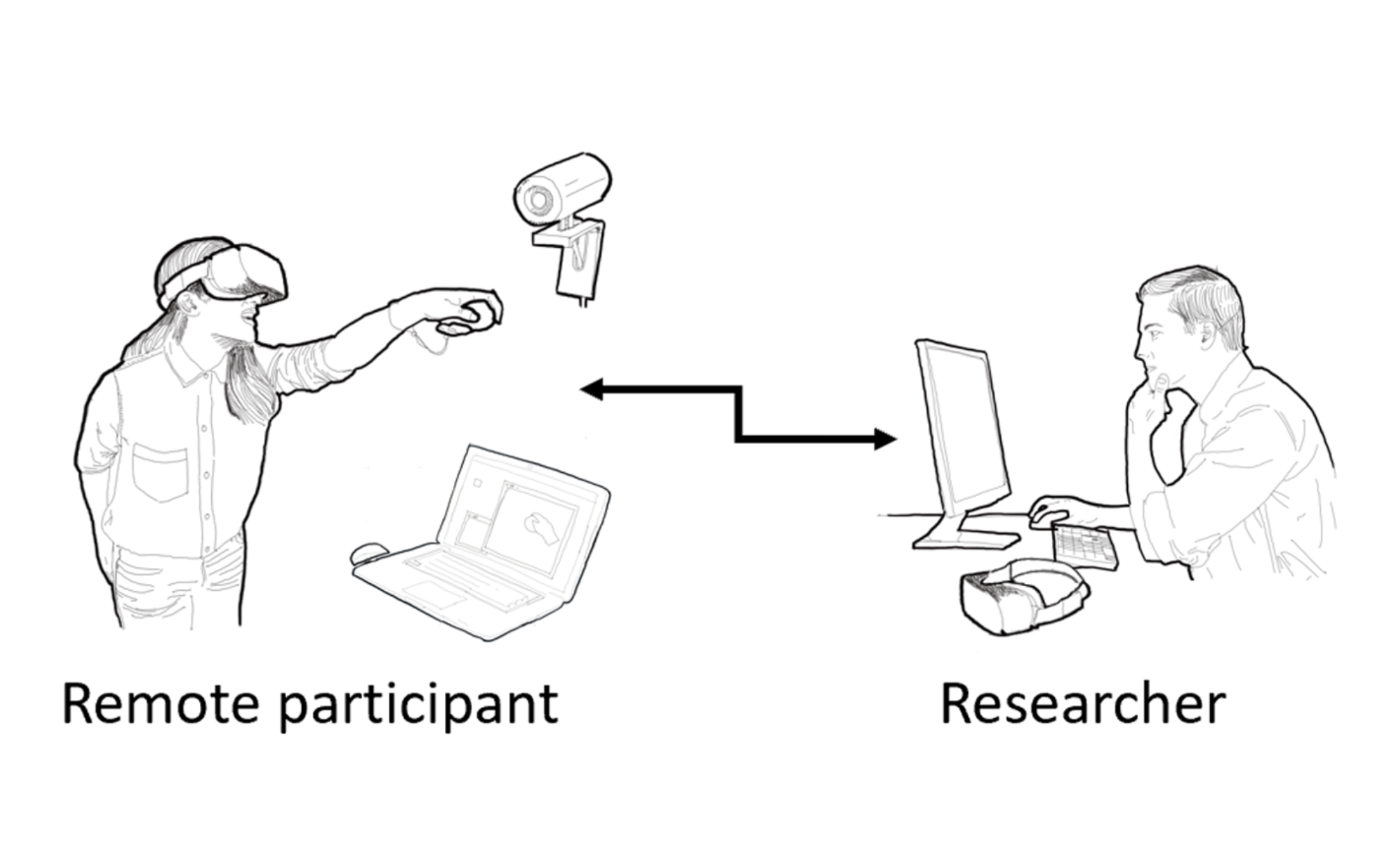
User studies play a critical role in human subject research, including human-computer interaction. Virtual reality (VR) researchers tend to conduct user studies in-person at their laboratory, where participants experiment with novel equipment to complete tasks in a simulated environment, which is often new to many. However, due to social distancing requirements in recent years, VR research has been disrupted by preventing participants from attending in-person laboratory studies. On the other hand, affordable head-mounted displays are becoming common, enabling access to VR experiences and interactions outside traditional research settings. Recent research has shown that unsupervised remote user studies can yield reliable results, however, the setup of experiment software designed for remote studies can be technically complex and convoluted. We present a novel open-source Unity toolkit, RemoteLab, designed to facilitate the preparation of remote experiments by providing a set of tools that synchronize experiment state across multiple computers, record and collect data from various multimedia sources, and replay the accumulated data for analysis. This toolkit facilitates VR researchers to conduct remote experiments when in-person experiments are not feasible or increase the sampling variety of a target population and reach participants that otherwise would not be able to attend in-person.
-
ASSETS '22 Workshop 5 Oct 2022
Towards Semi-automatic Detection and Localization of Indoor Accessibility Issues using Mobile Depth Scanning and Computer Vision
To help improve the safety and accessibility of indoor spaces, researchers and health professionals have created assessment instruments that enable homeowners and trained experts to audit and improve homes. With advances in computer vision, augmented reality (AR), and mobile sensors, new approaches are now possible. We introduce RASSAR (Room Accessibility and Safety Scanning in Augmented Reality), a new proof-of-concept prototype for semi-automatically identifying, categorizing, and localizing indoor accessibility and safety issues using LiDAR + camera data, machine learning, and AR. We present an overview of the current RASSAR prototype and a preliminary evaluation in a single home.
-

CSCW '22 29 April 2022
How Should the Agent Communicate to the Group? Communication Strategies of a Conversational Agent in Group Chat Discussions
In online group discussions, balanced participation can improve the quality of discussion, members' satisfaction, and positive group dynamics. One approach to achieve balanced participation is to deploy a conversational agent (CA) that encourages participation of under-contributing members, and it is important to design communication strategies of the CA in a way that is supportive to the group. We implemented five communication strategies that a CA can use during a decision-making task in a small group synchronous chat discussion. The five strategies include messages sent to two types of recipients (@username vs. @everyone) crossed by two separate channels (public vs. private), and a peer-mediated strategy where the CA asks a peer to address the under-contributing member. Through an online study with 42 groups, we measured the balance of participation and perceptions about the CA by analyzing chat logs and survey responses. We found that the CA sending messages specifying an individual through a private channel is the most effective and preferred way to increase participation of under-contributing members. Participants also expressed that the peer-mediated strategy is a less intrusive and less embarrassing way of receiving the CA's messages compared to the conventional approach where the CA directly sends a message to the under-contributing member. Based on our findings, we discuss trade-offs of various communication strategies and explain design considerations for building an effective CA that adapts to different group dynamics and situations.
-

IEEE VR '22 20 April 2022
User Preference for Navigation Instructions in Mixed Reality
Current solutions for providing navigation instructions to users who are walking are mostly limited to 2D maps on smartphones and voice-based instructions. Mixed Reality (MR) holds the promise of integrating navigation instructions directly in users’ visual field, potentially making them less obtrusive and more expressive. Current MR navigation systems, however, largely focus on using conventional designs such as arrows, and do not fully leverage the technological possibilities. While MR could present users with more sophisticated navigation visualizations, such as in-situ virtual signage, or visually modifying the physical world to highlight a target, it is unclear how such interventions would be perceived by users. We conducted two experiments to evaluate a set of navigation instructions and the impact of different contexts such as environment or task. In a remote survey (n = 50), we collected preference data with ten different designs in twelve different scenarios. Results indicate that while familiar designs such as arrows are well-rated, methods such as avatars or desaturation of non-target areas are viable alternatives. We confirmed and expanded our findings in an in-person virtual reality (VR) study (n = 16), comparing the highest-ranked designs from the initial study. Our findings serve as guidelines for MR content creators, and future MR navigation systems that can automatically choose the most appropriate navigation visualization based on users’ contexts.
-

CHI '22 29 April 2022
🏆 Honorable Mention
Hand Interfaces: Using Hands to Imitate Objects in AR/VR for Expressive Interactions
Augmented reality (AR) and virtual reality (VR) technologies create exciting new opportunities for people to interact with computing resources and information. Less exciting is the need for holding hand controllers, which limits applications that demand expressive, readily available interactions. Prior research investigated freehand AR/VR input by transforming the user’s body into an interaction medium. In contrast to previous work that has users’ hands grasp virtual objects, we propose a new interaction technique that lets users’ hands become virtual objects by imitating the objects themselves. For example, a thumbs-up hand pose is used to mimic a joystick. We created a wide array of interaction designs around this idea to demonstrate its applicability in object retrieval and interactive control tasks. Collectively, we call these interaction designs Hand Interfaces. From a series of user studies comparing Hand Interfaces against various baseline techniques, we collected quantitative and qualitative feedback, which indicates that Hand Interfaces are effective, expressive, and fun to use.
-

CHI '22 29 April 2022
ImageExplorer: Multi-Layered Touch Exploration to Encourage Skepticism Towards Imperfect AI-Generated Image Captions
Blind users rely on alternative text (alt-text) to understand an image; however, alt-text is often missing. AI-generated captions are a more scalable alternative, but they often miss crucial details or are completely incorrect, which users may still falsely trust. In this work, we sought to determine how additional information could help users better judge the correctness of AI-generated captions. We developed ImageExplorer, a touch-based multi-layered image exploration system that allows users to explore the spatial layout and information hierarchies of images, and compared it with popular text-based (Facebook) and touch-based (Seeing AI) image exploration systems in a study with 12 blind participants. We found that exploration was generally successful in encouraging skepticism towards imperfect captions. Moreover, many participants preferred ImageExplorer for its multi-layered and spatial information presentation, and Facebook for its summary and ease of use. Finally, we identify design improvements for effective and explainable image exploration systems for blind users.
-
CSCW '21 18 October 2021
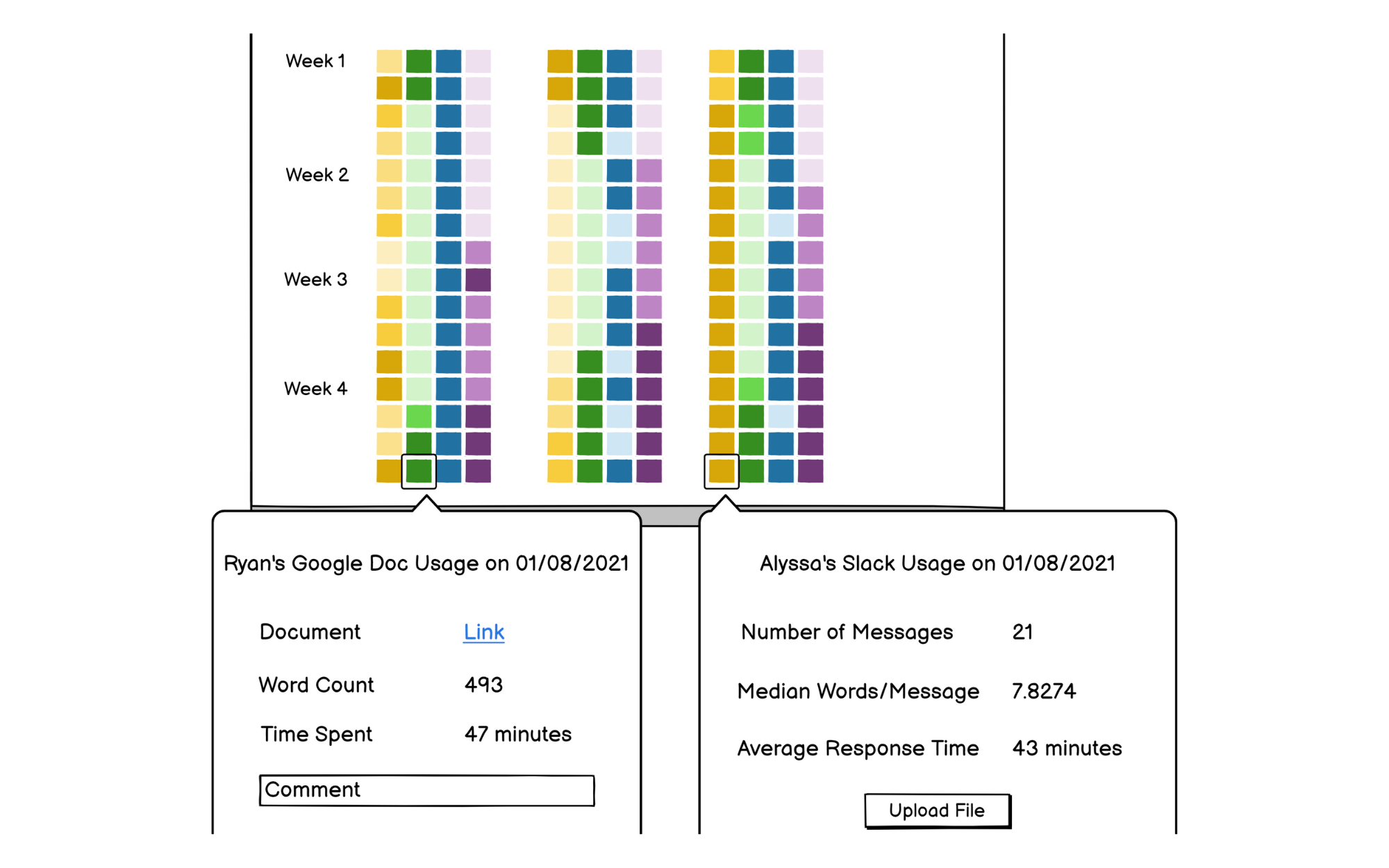
Challenges and Opportunities for Data-Centric Peer Evaluation Tools for Teamwork
Peer evaluations are critical for assessing teams, but are susceptible to bias and other factors that undermine their reliability. At the same time, collaborative tools that teams commonly use to perform their work are increasingly capable of logging activity that can signal useful information about individual contributions and teamwork. To investigate current and potential uses for activity traces in peer evaluation tools, we interviewed (N=11) and surveyed (N=242) students and interviewed (N=10) instructors at a single university. We found that nearly all of the students surveyed considered specific contributions to the team outcomes when evaluating their teammates, but also reported relying on memory and subjective experiences to make the assessment. Instructors desired objective sources of data to address challenges with administering and interpreting peer evaluations, and have already begun incorporating activity traces from collaborative tools into their evaluations of teams. However, both students and instructors expressed concern about using activity traces due to the diverse ecosystem of tools and platforms used by teams and the limited view into the context of the contributions. Based on our findings, we contribute recommendations and a speculative design for a data-centric peer evaluation tool.
-

ICMI '21 18 October 2021
What’s This? A Voice and Touch Multimodal Approach for Ambiguity Resolution in Voice Assistants
Human speech often contains ambiguity stemming from the use of demonstrative pronouns (DPs), such as “this” and “these.” While we can typically decipher which objects of interest DPs are referring to based on context, modern day voice assistants (VAs – such as Google Assistant and Siri) are yet unable to process queries containing such ambiguity. For instance, to humans, a question such as “how much is this?” can be clarified through visual reference (e.g., a buyer gestures to the seller the object they would like to purchase). To bridge this gap between human and machine cognition, we built and examined a touch + voice multimodal VA prototype that enables users to select key spatial information to embed as context and query the VA. The prototype converts results of mobile, real-time object recognition and optical character recognition models into augmented reality buttons that represent features. Users can interact with and modify the selected features through a word grid. We conducted a study to investigate: 1) how touch performs as an additional modality to resolve ambiguity in queries, 2) how users use DPs when interacting with VAs, and 3) how users perceive a VA that can understand DPs. From this procedure we found that as the query becomes more complex, users prefer the multimodal VA over the standard VA without experiencing elevated cognitive load. Additionally, even though it took some time getting used to, many participants eventually became comfortable with using DPs to interact with the multimodal VA and appreciated the improved human-likeness of human-VA conversations.
-
ASSETS '21 Demo 17 Oct 2021
Image Explorer: Multi-Layered Touch Exploration to Make Images Accessible
Blind or visually impaired (BVI) individuals often rely on alternative text (alt-text) in order to understand an image; however, alt-text is often missing or incomplete. Automatically-generated captions are a more scalable alternative, but they are also often missing crucial details, and, sometimes, are completely incorrect, which may still be falsely trusted by BVI users. We hypothesize that additional information could help BVI users better judge the correctness of an auto-generated caption. To achieve this, we present Image Explorer, a touch-based multi-layered image exploration system that enables users to explore the spatial layout and information hierarchies in an image. Image Explorer leverages several off-the-shelf deep learning models to generate segmentation and labeling results for an image, combines and filters the generated information, and presents the resulted information in hierarchical layers. In a pilot study with three BVI users, participants used Image Explorer, Seeing AI, and Facebook to explore images with auto-generated captions of diverging quality, and judge the correctness of the captions. Preliminary results show that participants made more accurate judgements about the correctness of the captions when using Image Explorer, although they were highly confident about their judgement regardless of the tool used. Overall, Image Explorer is a novel touch exploration system that makes images more accessible for BVI users by potentially encouraging skepticism and enabling users to independently validate auto-generated captions.
-

LAK21 Short Paper 12 April 2021
Explorations of Designing Spatial Classroom Analytics with Virtual Prototyping
Despite the potential of spatial displays for supporting teachers’ classroom orchestration through real-time classroom analytics, the process to design these displays is a challenging and under-explored topic in the learning analytics (LA) community. This paper proposes a mid-fidelity Virtual Prototyping method (VPM), which involves simulating a classroom environment and candidate designs in virtual space to address these challenges. VPM allows for rapid prototyping of spatial features, requires no specialized hardware, and enables teams to conduct remote evaluation sessions. We report observations and findings from an initial exploration with five potential users through a design process utilizing VPM to validate designs for an AR-based spatial display in the context of middle-school orchestration tools. We found that designs created using virtual prototyping sufficiently conveyed a sense of three-dimensionality to address subtle design issues like occlusion and depth perception. We discuss the opportunities and limitations of applying virtual prototyping, particularly its potential to allow for more robust co-design with stakeholders earlier in the design process.
-
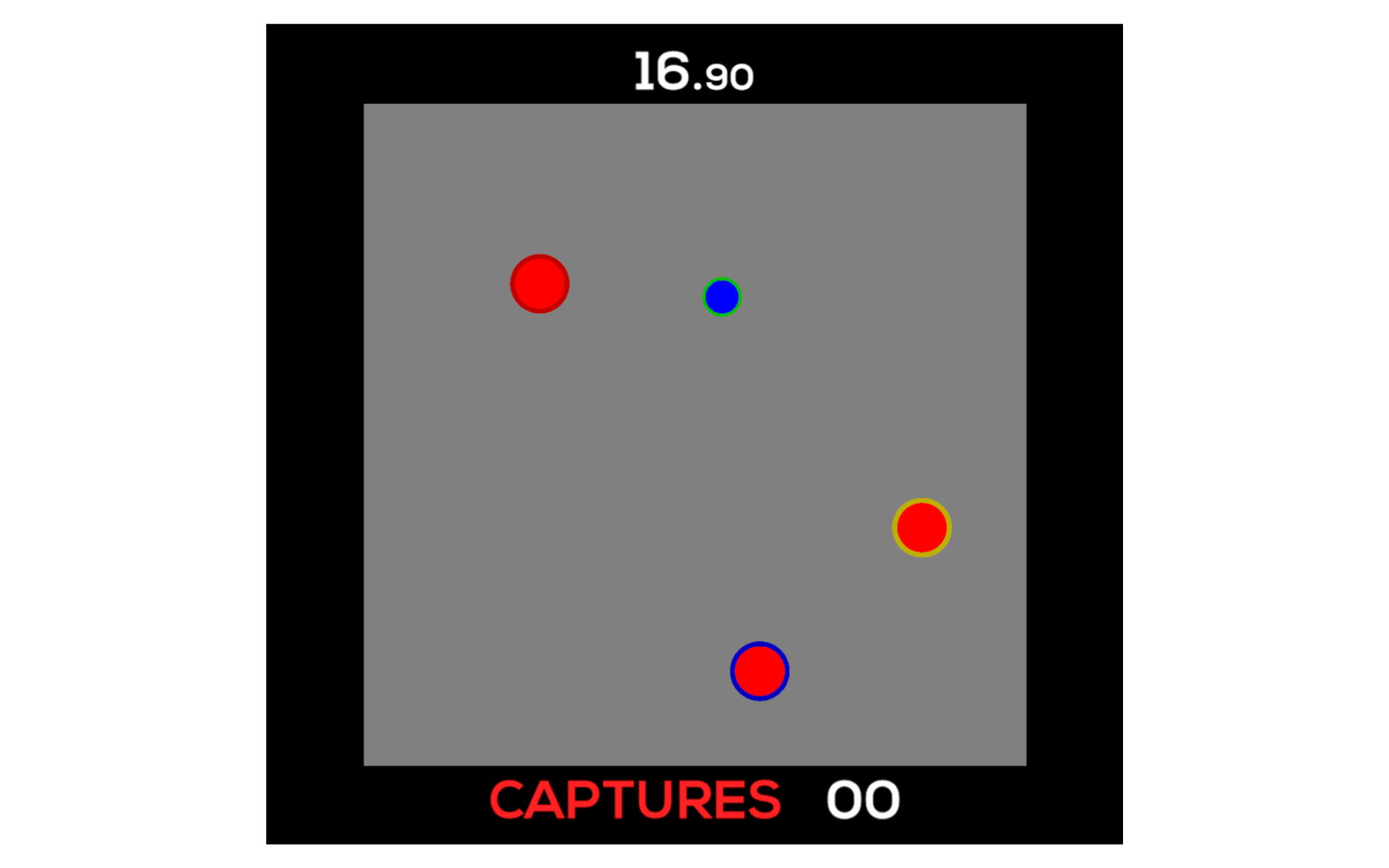
SPIE '20 21 April 2020
Measuring complacency in humans interacting with autonomous agents in a multi-agent system
With advances in machine learning, autonomous agents are increasingly able to navigate uncertain operational environments, as is the case within the multi-domain operations (MDO) paradigm. When teaming with humans, autonomous agents may flexibly switch between passive bystander and active executor depending on the task requirements and the actions being taken by partners (whether human or agent). In many tasks, it is possible that a well-trained agent's performance will exceed that of a human, in part because the agent's performance is less likely to degrade over time (e.g., due to fatigue). This potential difference in performance might lead to complacency, which is a state defined by over-trust in automated systems. This paper investigates the effects of complacency in human-agent teams, where agents and humans have the same capabilities in a simulated version of the predator-prey pursuit task. We compare subjective measures of the human's predisposition to complacency and trust using various scales, and we validate their beliefs by quantifying complacency through various metrics associated with the actions taken during the task with trained agents of varying reliability levels. By evaluating the effect of complacency on performance, we can attribute a degree of variation in human performance in this task to complacency. We can then account for an individual human's complacency measure to customize their agent teammates and human-in-the-loop requirements (either to minimize or compensate for the human's complacency) to optimize team performance.
Hobbies
Revamping... Coming Soon!